坂田さんに言われたので、中々短時間でAIを説明する事は難しいですが、あえて社内の状況に合わせて説明を作ってみました。
AIは以前Fuzzy(ファジー)と言っていた時があります。考え方は今と同じですが、ハードとソフトの処理能力が遅かったので閾値を超えて何かを入切りするといった制御からどちらかと言えばAもしくはBといった判断をさせていました。
さて社内でお馴染みの計測装置は温度が何度になったら入り切り、シーケンサーを使って何かの閾値を超えてある時間が経過したら動作するといった制御です。
例えばダイヤル温度計の様なアナログの入出力は特にノイズを取除く制御も必要無いです。
問題はデジタル機器はセンサーの測定やCPUの演算の際に熱等のノイズで出力にバラつきが出ます。



AIは以前Fuzzy(ファジー)と言っていた時があります。考え方は今と同じですが、ハードとソフトの処理能力が遅かったので閾値を超えて何かを入切りするといった制御からどちらかと言えばAもしくはBといった判断をさせていました。
さて社内でお馴染みの計測装置は温度が何度になったら入り切り、シーケンサーを使って何かの閾値を超えてある時間が経過したら動作するといった制御です。
例えばダイヤル温度計の様なアナログの入出力は特にノイズを取除く制御も必要無いです。
問題はデジタル機器はセンサーの測定やCPUの演算の際に熱等のノイズで出力にバラつきが出ます。

デジタル機器は測定のインターバル(サンプリング)が高速で(毎秒数十回以上)で上記の様にばらついてしまいます。
そこでサンプリングを例えば1秒毎にしてバラつきをとるのですが、例えば26度でONとすると25.9度と26度を行ったり来たりする時の事を考慮します。チャタリング防止。
ここまでは昭和の制御…
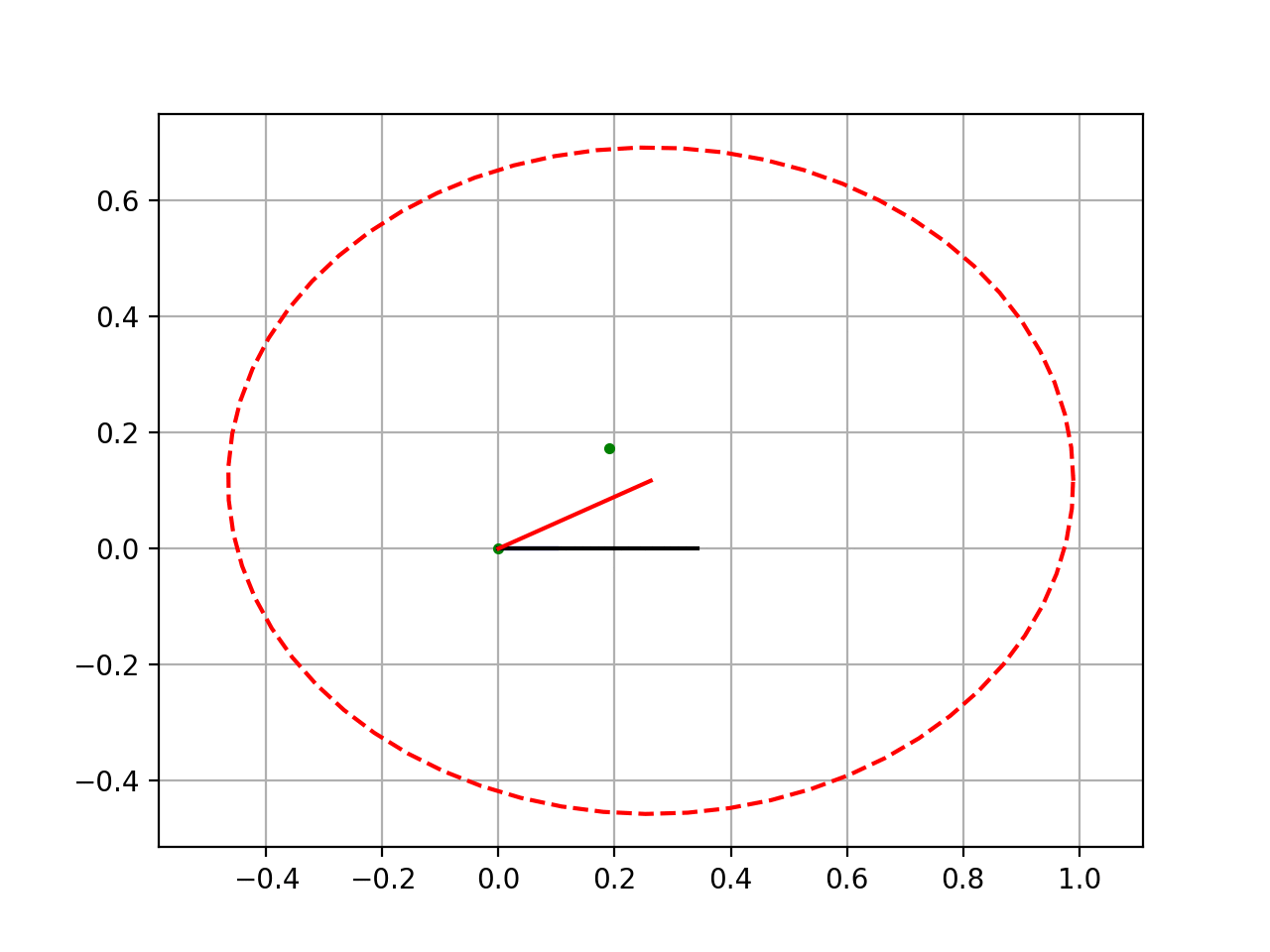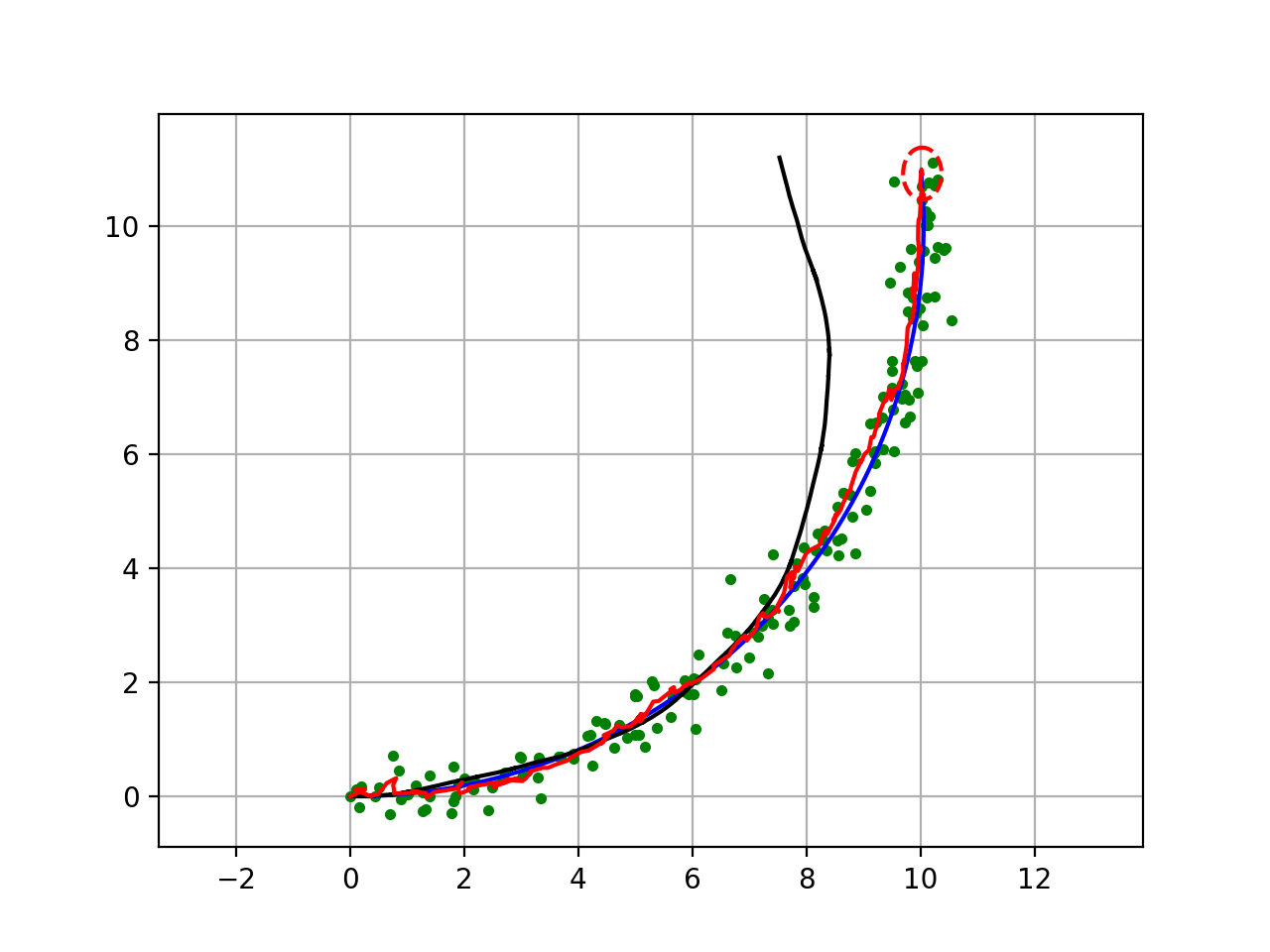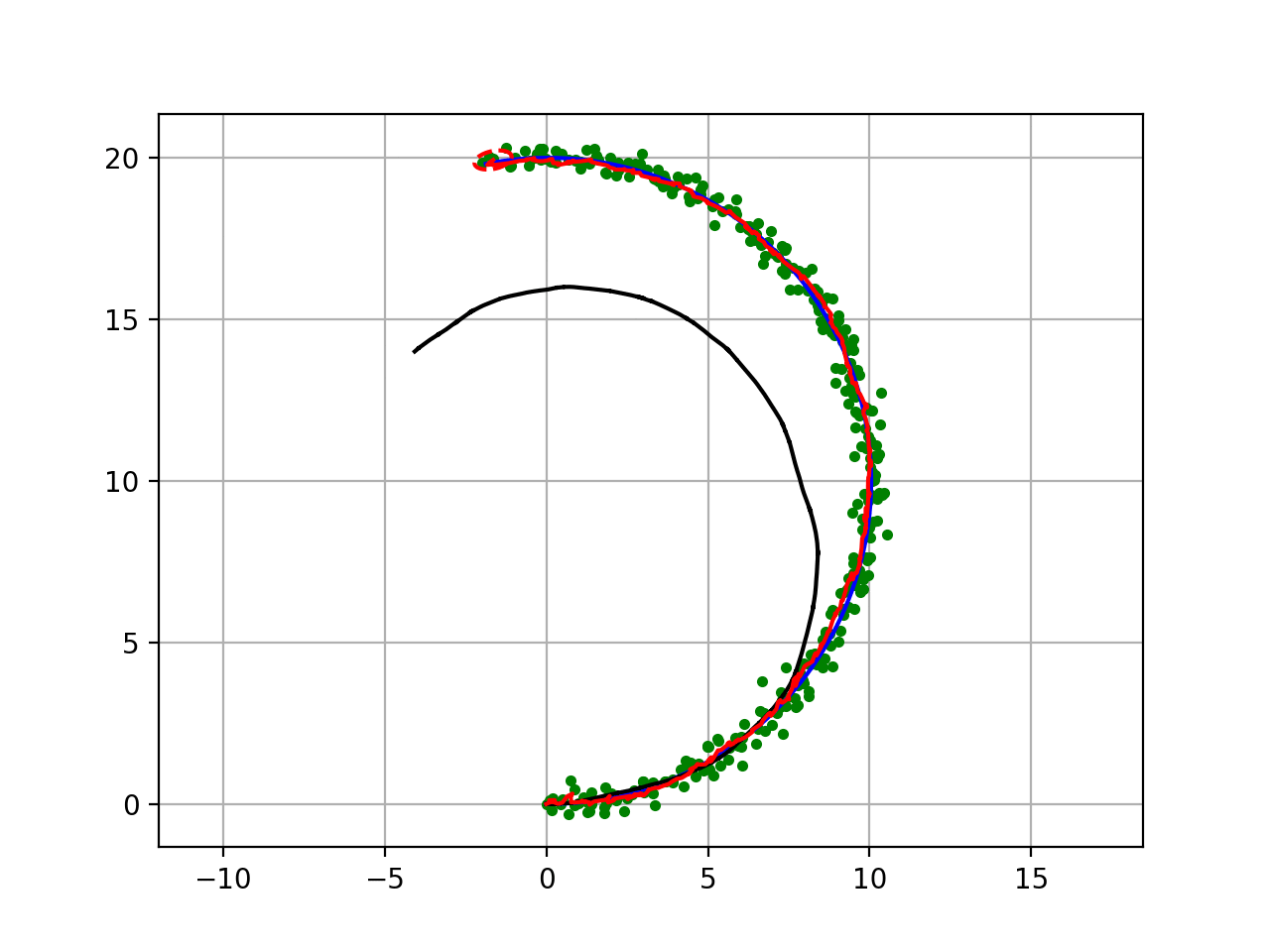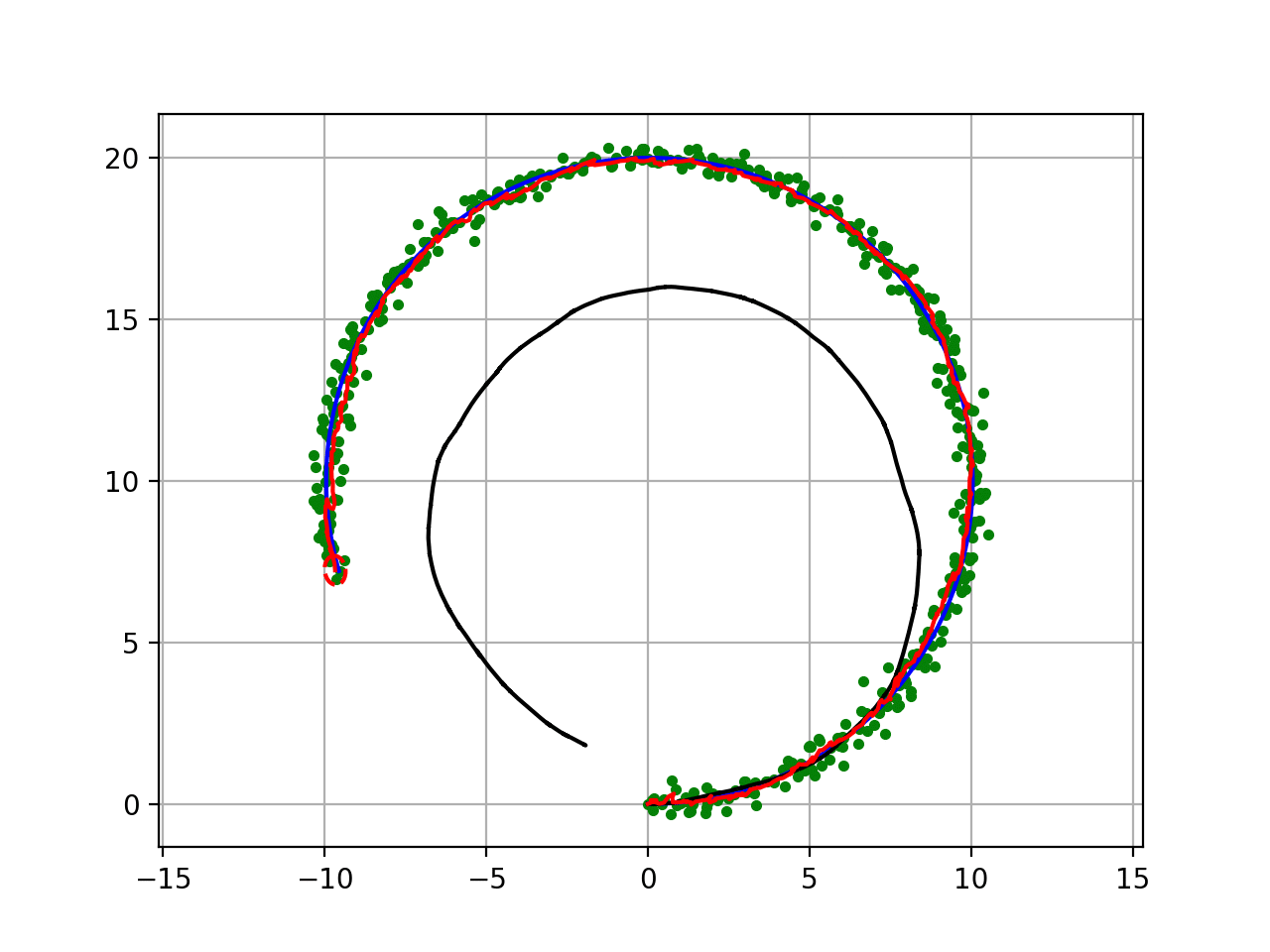
実際の温度自体(実際の温度)はそうなる事(25.9-26-26-25.9-25.8が数秒間隔)は稀です。現代制御はそもそも、実際の温度をセンサーからノイズを除いて極力正確に抽出します。
26度の1分後に60度になる確率は低い(0%ではない事は確か)その可能性の高い温度を予測値(期待値)として扱います。
出力値を確率的な処理をするとこうなります。(正規分布図)
実際には急峻なカーブやなだらかなカーブだったりしますが、正規分布図の頂点の値が出力結果になります。
1秒後の期待値(予測値)、1分後の期待値、1時間後の期待値…
他の要素を加味するとより正確に実際の数値に近くなります。
なぜ期待値もしくは予測値かと言うと人間お風呂を沸かして入る時に100度になっているとは思いませんね。それは湯沸かし器を理解してそうならないであろうと予測(期待はしていないと思いますが…)している訳です。人工知能も同じ様に経験(学習)から予測します。
データが実際の値に近い若しくはその値であればその数値を使った次の予測は良い結果が得られます。ちゃんと学習すればテストに合格するようなものです。
AIの値はこれらの確率に基づいた数値によって成り立っています。
現在の計測装置のセンサー出力にこの予測値がなくても問題がある訳ではありませんが、予測値があれば機器の寿命や関連機器の調子が分かったりとサービスは向上します。
詳細の説明は長くなるので…
具体的な例でスマホでのグーグルマップの自己位置推定があります。

GPSで位置を取得するのですが、建物の中はGPSの信号は届きません。次に携帯電話の基地局はWiFiステーションの位置データから現在の位置を割り出す。移動していれば携帯の中の加速度センサー、ジャイロセンサーでも補助します。
それらのデータから一番妥当な位置を表示します。
GPSのデータがノイズの影響で違う距離の位置を拾ったとしてもそれまでの位置データだセンサーデータからの移動距離を加味して導きだします。
またAI技術でわかりやすいのは迷惑メールのsort機能でしょう。
@迷惑メール.ドメインや3829isk2ji@nantoka.comは迷惑メールルールで迷惑メール.ドメインは受信しない、数字と記号のメールアドレスは受信しないとルールをつくれますが、ルールを作るとキリがないので迷惑メールのルールをサーバー側でその特徴をどんどん学習させます。未知の迷惑メールもその学習結果で回避出来ます。
株価のトレンド情報もAIとは言いませんが(AIと言う会社もありますが違うと思います。)ベイズ理論で成り立っています。どれだけ業績が良くても無制限に株価は上がりません。為替レートも日本列島が消滅しない限り$=1円や200円はありません。
保険会社の料率と配当もベイズ理論=確率論的予測値に基づいています。
でこれがみんなの給料や現在の仕事に役に立つのか?
これを確率論的な答えをすると、
①知らないで徳をする事はありません。
②より多くこれらを理解する事で損をする事はありません。
そんな事がAIやIoTになります。それを実践しています。
くどい説明はしてはいけないと何度も注意されていますが、長くなってすみません。


































{kind=link}