今後AIや機械学習と呼ばれるサービスの需要は様々な産業で増え続け、既存のサービスとの融合は益々重要になるでしょう。難解な技術を意識すること無く利用されるような社会になっていくのは時間の問題と思われます。
昨今この分野はインターネットが普及した時以来の大きな変革と理解されています。
過去、インターネット革命の際はパソコン(情報処理能力)やコンピューター通信(ネットワーク)の普及は便利な情報検索やメールサービスの需要と合間って爆発的に進みました。
仕組み自体の理解はそれほど難しくものではなくパソコンとインターネットを理解出来なくても機器を購入する事でサービスを便利に利用出来ました。
AIや機械学習とは、ハード・ソフトが飛躍的に進化した現在、人間の神経学的な学習過程をコンピューターで処理し推論、判定をする事で利用出来るサービスです。その仕組みは最先端の論文で成り立っており一般に理解され難いものです。
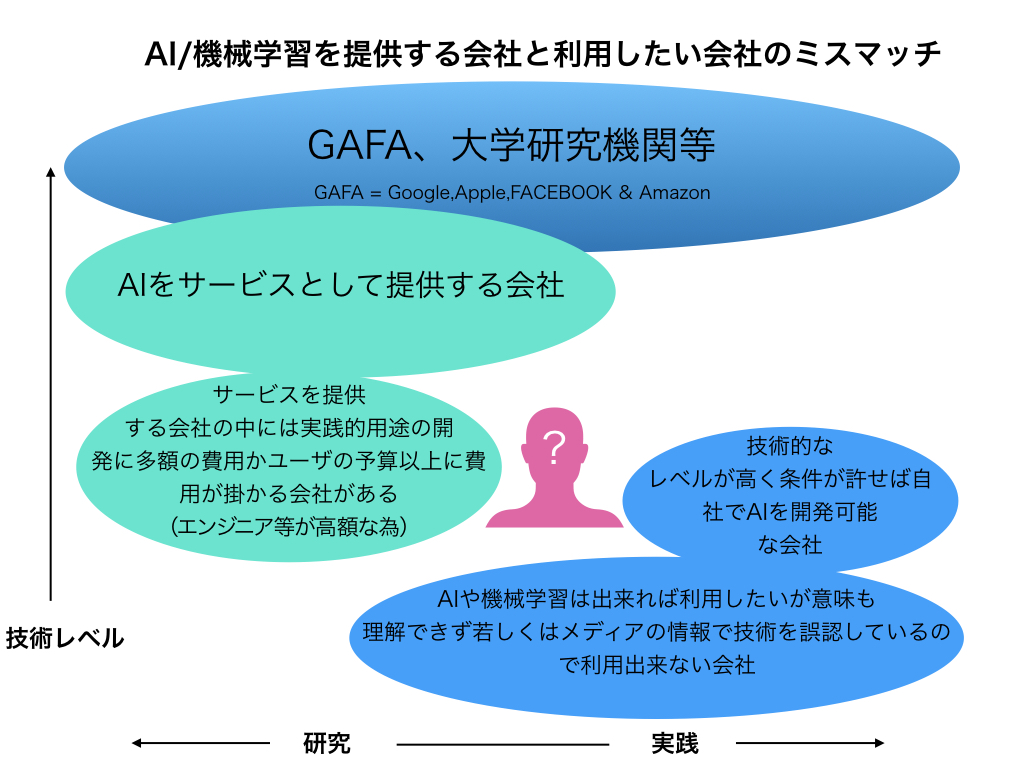
日本では人工知能と呼ばれ「万能な物」、「人間の職種が消滅する」、「コンピューターが自己学習して人間を支配する」等で誤解されやすいように思います(AIセミナーに参加している会社でも真にシステムを理解している会社は少ない様です。)
当社でこの技術を利用する為に書籍、インターネットの情報やセミナーを通じて知り得た情報で実現可能なサービス、出来ないサービスか現時点では難しいサービスはある程度理解できました。さらに、実現可能でも費用対効果を良く考えないといけない事も見えて来ました。それなりに時間を掛けて勉強していますが、進化のスピードは非常に早くより難解になっています。(時間の問題ですが、効率良く基礎技術の習得が必須、それでもでかなりの時間がを要し、参考書等は論文がベース。統計学や確率論の基礎理解や行列演算等の数学の知識が無ければ理解は難しいレベルの資料を読み進めています。)ここは避けて通れず、参考書で要約した情報を理解する事は実質無理で、これらを情報を元に、学習と実践を繰り返しながら根気よく進めている状況です。
*AIと言う単語は誤解されやすく極力その呼び方を避けています。今は機械学習(MACHINE LEARNING)を使う様にしています。諸刃の剣で一般の人には理解されやすい反面、誤解も生じています。
俗にAIサービスを提供する会社にだいたい300−500万円払えば大体のサービスは何とか形になりますが本質の技術の理解が無ければそれ以上の発展や応用は不可能。そもそも機械学習は再学習を繰り返して推論の精度を上げてサービスを向上するものなので、継続した支出が必要で(ここを理解していない会社は多いです)、結局継続が難しくなり、自社でシステムを理解しながら進めていかないと費用対効果が出ない状況。つまり開発初期は、そのサービスを提供会社に依頼したとしても、継続して改善する部分は極力自社運用が必要だということです。
上場企業であれば予算がありある程度の費用対効果は見込めますがそれ以外の中小の会社にはかなり難しい金額だと思います。
弊社も含めて困っている会社のイメージはこんな感じ
ザクっと足らない技術を習得する為の本だけでもこの量
これらの情報を読み進めて行く中で技術は早いスピードで進化しておりある程度発表されたばかりの論文も理解する必要があります。理解はかなり専門的な知識が必要。
つまり今から始めるのは赤い部分。その後どちらの方向に進むか予算を考えながら進みます。
セミナー等であたりを見渡すと同じ様な会社は多く、これから実践するものを共有できれば社会の役に立つのではないかと考えました。
なにで実現するかと言うと、今最新のエッジとして有名なnvidia Jetson Xavier(写真右側)やTX2(機械学習用エッジとしては企画的低コストー写真左側)
開発環境は全てオープンソースでメーカーからのSDKも豊富。
とYOLOと言うフレームワークここ2、3年流行って来ている新しいフレームワーク
(YOLO = You Only Look Once <- You only live once = 人生一度限りをもじってます)
それぞれトヨタの様な大企業からスタートアップと呼ばれるAI関連の会社で幅広く使われているハードとソフトで柔軟性があり色々な応用が可能。
ここまではどの会社でも出来るので、ここに電機機器を扱う会社ならではの技術であるサーモグラフィーの技術を使って機械学習と推論を実践します。
ハードウェアは一般に購入可能で今回このシステムを共有する個々の会社で購入して頂きます。ハードウェア総額で10万円〜30万円程度(nvidiaの開発者登録をすれば〜20万円で済みます。)
インストールを出来ない場合はインストールのサポート費として10万円〜15万円申し受けます。
Do it yourself !なのでこれらのハード以外に費用は殆ど掛かりません。ハード自体の需要は高く使えなくてもオークションで今なら半額で簡単に処分できる上それ以外のROS(ロボット用の基本ソフトもインストールも可能)で損をする事は殆どありません。
これとは別にnvidia GPUを搭載したLinuxパソコンがホストPCとしてXavierやTX2にソフトウェアをインストールする為に用意する必要があります。既存のパソコンにnvidiaのグラフィックカードを追加して無償のUbuntuを別パーテションにインストールする事で新たにPCを購入する必要はありません。但しトラブルが出た際の事を考えると十数万円のパソコンを揃えた方が無難ではあります。
また今回独自に使っているサーモグラフィーの技術は第6の感覚として知られている技術で高コストな技術を安価に実現出来るLepton開発環境を利用して現在使用しているソフトとハードは米国サーモグラフィーメーカーの開発者ブログにも載るお墨付きのものです。
またTokyo Maker Faire2017と2018でもこのサーモグラフィー技術を使った展示発表。
今回のシステムの為に新たにサーモグラフィー機器とnvidiaの機器と有線、無線接続用ラズベリーPI 3B+とそのソフトウェアを開発。
*11月15日現在基本部分の90%は完成して調整中、サーモセンサーからPi3との有線接続の部分はほぼ一からの開発で調整にまだまだ時間がかかります。
JECA FAIRで無線LAN機器が多すぎて接続失敗したので有線LANを使えるようにソフトもハードも変更したのでそれに時間が掛かっています。思いの外、サーモセンサー挙動と新しい機器との調整に悪戦苦闘中。
また出来るだけキャッチーなデモの見せ方の検討中。
判定を各色LEDで表示は直ぐに出来ますが、見た目がショボい感じ。時間的に制約がありますが、Text to speechファンクションを使って判定結果を音声出力等々検討中。
PI3より小型のPI Zeroはサーモグラフィーの可視化の為の処理スピード不足で断念!
ソフトウェアの殆どはオープンソースで無料で尚且つ一部独自に開発した認識スピードアップのアドオンも無償で公開します。
それぞれの取り扱いやインストールする際の注意点等もブログに載せて説明。
(ある程度のソフトウェア、ハードウェアの知識は必要。その知識はAIや機械学習を事業と行う以上最低限必要なレベル。)
これらを使えば機械学習の教師付き学習データを独自にアノテーションして学習させてその推論を検証再学習が可能。その過程で機械学習のknow-howを蓄積、応用技術の開発また同じハードウェアでTenser flow、ChainerやPyTorchなど他のフレームワークへも柔軟に変更可能。
このサービスを共有する事で同じ中小企業で手軽に機械学習を始められその中で得られた知識でそれぞれの会社で応用可能な技術開発が低コスト可能になる。
当社としてはこのサービスを提供する事によりAIや機械学習技術をより多くの企業が実現可能になる手助けをする事でそれぞれの分野でこの技術を普及する事で社会の役立つと考えます。
また下記コンテスト要件も満たす事が出来る。
1)実現性 既存ビジネスと差別化できており、明確かつ現実的な内容である。
AIの導入をサポートするという視点でシステムを組んでいるので既存のハードやソフトを販売するビジネスモデルとは差別化できている。基本的な部分は実現出来ている。
2)収益性 将来的に収益の見込める内容であること。
当社はソフト的なサポートをするので、基本ユーザーのDIYなので共鳴する会社が増えても比例して収益が増える事はないが、それぞれの会社でAIや機械学習が実践、理解が進み発展する事で社会に貢献出来る。
3)ユーザー視点 ユーザーの価値創造が明確な内容であること。
そもそも自社用に開発したものなのでユーザー視点である事。それぞれのユーザーがこのサービスを利用する事でそれぞれの企業でAIや機械学習を使った付加価値の創造が可能。
4)社会性 社会課題の解決に向けた内容であること。
現在のAIや機械学習のミスマッチングを改善してこの技術の普及の助けになる事で社会に貢献出来る。
5)技術性 独創的な技術を取り入れた内容であること。
2018年の時点の最新のソフトとハードを取り入れました。
また様々な応用の効く独自に開発したサーモグラフィーを利用したシステムも併用出来る様にした。またその内容は殆ど公開予定。この点に関しては現時点で日本以外の国を含めて誰にも負けない自信あります。メーカーを含めて他社は単純なRGB画像出力に対して生データ(各ポイントの温度データ)をカラーパレットで8−9FPSで画像化しています。
オリジナルメーカーの開発者ページに掲載されているのもここがポイントです。iPhoneアプリのダウンロードは日本より北米で圧倒的に多く支持されています。日本の6倍以上!オーストライアだけでも日本の倍です。
これで3つの要件を満たしました。
①当社独自のAIと機械学習の開発
②大阪商工会議所 第二回AIコンテストの申し込み
③同じ様な問題を抱える会社と技術を共有する事での社会貢献
謝辞
この度このプロジェクトを進めるにあたり公私ともに小野武様には多大なご協力を頂きこの場をお借りして厚くお礼を申し上げます。
またこれらの機械学習フレームワーク、学習データソフトをオープンソースとして提供されている個人、団体へも畏敬の念を禁じ得ません。ありがたく使わせて頂きます。














































{kind=link}